Qu’est-ce que Kafka?
Apache Kafka est une plateforme open source gratuite distribuée pour diffuser de la donnée en continu, permettant de publier, mémoriser, traiter et s’abonner à des flux en temps réel.
Kafka a été développée par Linkedin en 2011, et l’idée était de contrôler de gros flux de données en provenance de plusieurs sources et les renvoyer à plusieurs utilisateurs.
L’utilisation de Kafka
Dans le cas de Linkedin, Kafka sert a réaliser des statistiques, par exemple :
- quand un utilisateur déroule le Read More sur un article
- s’il clique sur les commentaires d’un post afin de les lire
- s’il clique sur des images ou des liens dans des posts
- s’il scroll son fils d’actualité
- ect…
Toutes les informations concernant les utilisateurs s’appellent des évènements, et sont enregistrées afin d’être converties en statistiques.
Volume de donnees sur Kafka
Et bien sûr, ces informations représentent un très gros volume de données puisque le système tracke chaque mouvement de chaque utilisateur. Pour l’anecdote, on compte environ 134 millions d’utilisateurs actifs chaque jour sur le réseau social Linkedin. La technologie de Kafka traque tout ce monde. Ce n’est pas un problème car Kafka est justement conçu pour traiter de très gros flux de données.
Avec une machine ayant une bonne CPU et RAM, ainsi que plusieurs brokers de Kafka (nous verrons en détails ce que c’est par la suite), il est possible d’atteindre les 1 milliards d’évènements par jour. Ou si vous voulez, vous pouvez traiter 200 millions d’évènements par heure. Tout dépendra de la configuration de votre machine.
Nous allons voir un cas d’exemple afin de mieux vous définir les termes de Kafka.
Exemple pour Kafka
Un utilisateur envoie un message privé à un ami sur une application. Le frontend a été créer en HTML, CSS et Javascript tandis que le Backend utilise du Java.
Le Frontend produit un message, et celui-ci appelle une API en direction du Backend. Le Backend reçoit le message et l’utilisateur qui a envoyé ce message. On envoie ces informations (qui sont appeler un message, un record ou un évènement) dans le Producer de Kafka. Il est stocké dans un topic (sur qui on a précisé le nom lors de l’envoi au producer) lui-même composé de partitions. Il est ensuite consommé dans le Consumer, parce qu’on est abonné au topic. Puis si on veut, on peut faire une réponse de retour au Frontend, comme afficher le message qui a été envoyer, dans l’historique.
Si cette description était floue, c’est normal. Il nous reste à définir les termes de Kafka afin que vous puissiez comprendre comment l’outil fonctionne.
💭 Pour savoir ce qu’est une API, vous pouvez lire cet article: Comprendre Postman, les API et les requetes.
L’intérêt de Kafka est que tout se passe tout de suite : le message qui est envoyé par un utilisateur apparaitra directement comme par magie dans l’historique de conversation sur le frontend, sans avoir eu besoin de recharger la page.
Kafka est donc idéal pour une application de messagerie instantanée, ou comme chez Linkedin, c’est un outil adapté pour traiter des statistiques sur un site internet. Bien entendu, Kafka serait inutile pour les petites structures et pour traiter de faibles flux de données.
Passons maintenant aux explications techniques de Kafka.
Vocabulaire de Kafka
Consumer & Producer
Record: c’est une unité de donnée. On l’appelle souvent message ou évènement, et elle est au format clé – valeur.
Consumer: entité qui lit des records depuis Kafka, selon le topic auquel on souscrit.
Producer: entité qui envois des données dans Kafka selon un nom de topic spécifié.
Broker : c’est un serveur Kafka dédié. Le producer et le consumer l’utilisent pour interagir ensemble. Par exemple, c’est le consumer qui va demander au broker
Il est possible de configurer plusieurs brokers pour pouvoir traiter plus de données.
⚠ Kafka recoit les données sous forme de STRING. Il est donc nécessaire de les sérialiser pour les envoyer au producer, et de les désérialiser lorsque le consumer les recoit afin de les traiter.
Evenements, topic & partition
Topic : ils regroupent des records (ou messages / évènements). On peut en avoir autant qu’on veut. Le producer envoi des records dans un topic (grâce à son nom), et le consumer va s’abonner aux topics souhaités. Des reception du message par le consumer, celui le traitera automatiquement car on se sera abonné au topic spécifié.
Il est possible de souscrire à plusieurs topics, et d’envoyer des records dans plusieurs d’entre eux. On peut aussi définir une quantité maximale de record dans un topic.
Chaque topic comporte plusieurs partitions.
Partitions : les topics se composent en plusieurs partitions. Pour donner un exemple vulgaire, une commode pourrait s’apparenter à un topic, et les tiroirs sont les partitions. Le systeme de partition ordonne les records à l’intérieur, et chaque nouveau record est ajouté à la fin. On ne sait pas dans quel ordre les records dans les partitions sont lues par les consumers, c’est aléatoire.
Mais une question se pose : Comment sait-on sur quel record ajouter une partition ? Eh bien en réalité cela va dépendre de la clé du record (pour rappel, les records sont des messages au format clé – valeur).
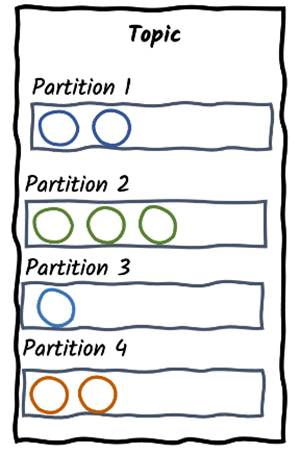
Offset : chaque record qui rentre dans une partition va recevoir un offset. Il s’agit en fait d’un ID unique, qui permet aux consumers de ne pas se perdre.
Il est impossible de supprimer des données au sein d’un topic, sauf si vous définissez une durée de rétention. C’est donc pratique si un utilisateur reçoit un message, mais qu’il n’est pas en mesure de le recevoir : le message va alors patienter dans le topic jusqu’à ce que ce soit possible de l’envoyer.
Schema registry & consumer group
Schema registry : un schéma définit la structure et le format de la donnée (du record). Le Schema Registry définit donc une portée dans laquelle les schémas peuvent évoluer. Il versionne les différents schémas avec un ID unique, et il permet de garder une cohérence de la structure des records dans les différents topics. Cela évite qu’on se retrouve avec des producers différents, qui produisent des données différentes dans le même topic.
Consumer group : il s’agit tout simplement d’un ensemble de consumers. Ils vont se coordonner pour ne pas lire les mêmes partitions au sein du même groupe. Il faudra alors configurer un groupe ID unique dans les paramètres de Kafka. Il faut avoir autant de consumers que de partitions.

Pour finir, Kafka est une technologie open-source très puissante qui vous permettra de traiter des milliers d’évènements par heure ou par minute. La prise en main peut être compliquée, c’est pour cela qu’il faut bien connaitre son fonctionnement en amont.